Federated RL in the DBMS
FeReD is a system that contrasts the performance of cross-device federation using Q-learning. It offers step-by-step guidance for in-DBMS SQLite implementation challenges for both horizontal and vertical data partitioning. FeReD also allows to contrast the Q-learning implementations in SQLite vs a standard Python implementation.
Description
Federated learning enables clients to enrich their locally trained models via updates performed by a coordination server based on aggregates of local models. There are multiple advances in methods and applications of federated learning, in particular in cross-device federation, where clients having limited data and computational resources collaborate in a joint learning problem. Given the constraint of limited resources in cross-device federation, we study the potential benefits of embedded in-DBMS learning, illustrated in a federated reinforcement learning problem. We demonstrate FeReD, a system that contrasts the performance of cross-device federation using Q-learning, a popular reinforcement learning algorithm. FeReD offers step-by-step guidance for in-DBMS SQLite implementation challenges for both horizontal and vertical data partitioning. FeReD also allows to contrast the Q-learning implementations in SQLite vs a standard Python implementation, by highlighting their learning performance, computational efficiency, succinctness and expressiveness. Thus, FeReD helps data scientists to make an informed decision regarding the configuration of a federated reinforcement learning protocol.
Federated Learning
From a top view, Federated Learning is a machine learning setting in which a central server is responsible for solving a learning task while making use of decentralized rich data from numerous sources (e.g. mobile devices, etc…). In this setting, the central server maintains a global model and has the role of coordinating the various participants (named as data owners or clients). These participants are made up of a wide variety of edge devices, including smart devices in the Internet of Things (IoT) or autonomous vehicles in the Internet of Vehicles (IoV). Each participant has its own level of hardware capabilities (computational power, communication architectures, storage) and they are independent of each other, located in different geographical areas. The selection of each participating device is done based on computing costs from the previous characteristics as well as specific device conditions (e.g. plugged in, fully charged, during night-time, etc…).
Distribution of Data
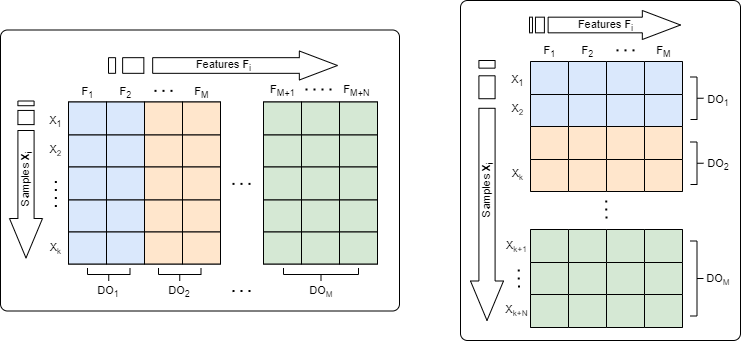
One important aspect of Federated Learning that affects the technical implementation of the system is the way the data is distributed across the devices. This distribution can fit into two categories, namely horizontal and vertical partitioning. In Horizontal Federated Learning (HFL), the datasets that participants have ownership of contain different samples, but these samples are described by a consistent set of features (data split by samples). On the contrary, in Vertical Federated Learning (VFL) the datasets contain the same set of samples but a different set of features (data split by features). For instance, each dataset contains the same kind of (intersecting) data for each different sample. The two types of partitioning are illustrated in the figure below in which the different colors represent the data owners.
Environment
The main focus is to implement the Q-learning algorithm, which was explained in Subsection 3.1.1, using off-the-shelf SQLite. In this thesis, we consider the popular Frozen Lake environment as the learning problem.
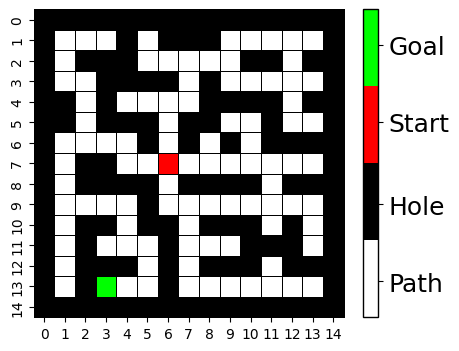
In this environment, an agent is asked to move through a frozen lake from a starting position to a goal. The agent may not be able to move to a desired position, which indicates an unsafe state (aka a “hole”). The action space consists of four possible actions (go 0:left, 1:up, 2:right, 3:down), and there is a simple function which rewards the agent with a value of −1 for each successful action, a value of −10 for each action leading to an unsafe state, and a reward of 100 for finding the goal.
Technical Challenges
Through this work, we implemented the Reinforcement Learning method known as Q-learning into purelly written SQLite expressions. Comparisons were made between the SQLite codebase and a purely Pythonic implementation, in order to identify key differences. Some of the challenged FeReD was called to solve were the following:
- Encoding iterations
- Creating a breaking condition for such iterations
- Generate random numbers
- Allow the implementation to adopt to both Horizontal and Vertical partitioning of data
- Implement the FederatedAveraging algorithm in SQLite
Visual Interface
FeReD comprises three distinct vertical zones. Zone A (Interaction), contains the federated settings as well as the Q-learning hyperparameters. Zone B (Setting) depicts the selected learning configuration and Zone C (Results) displays the results of training.
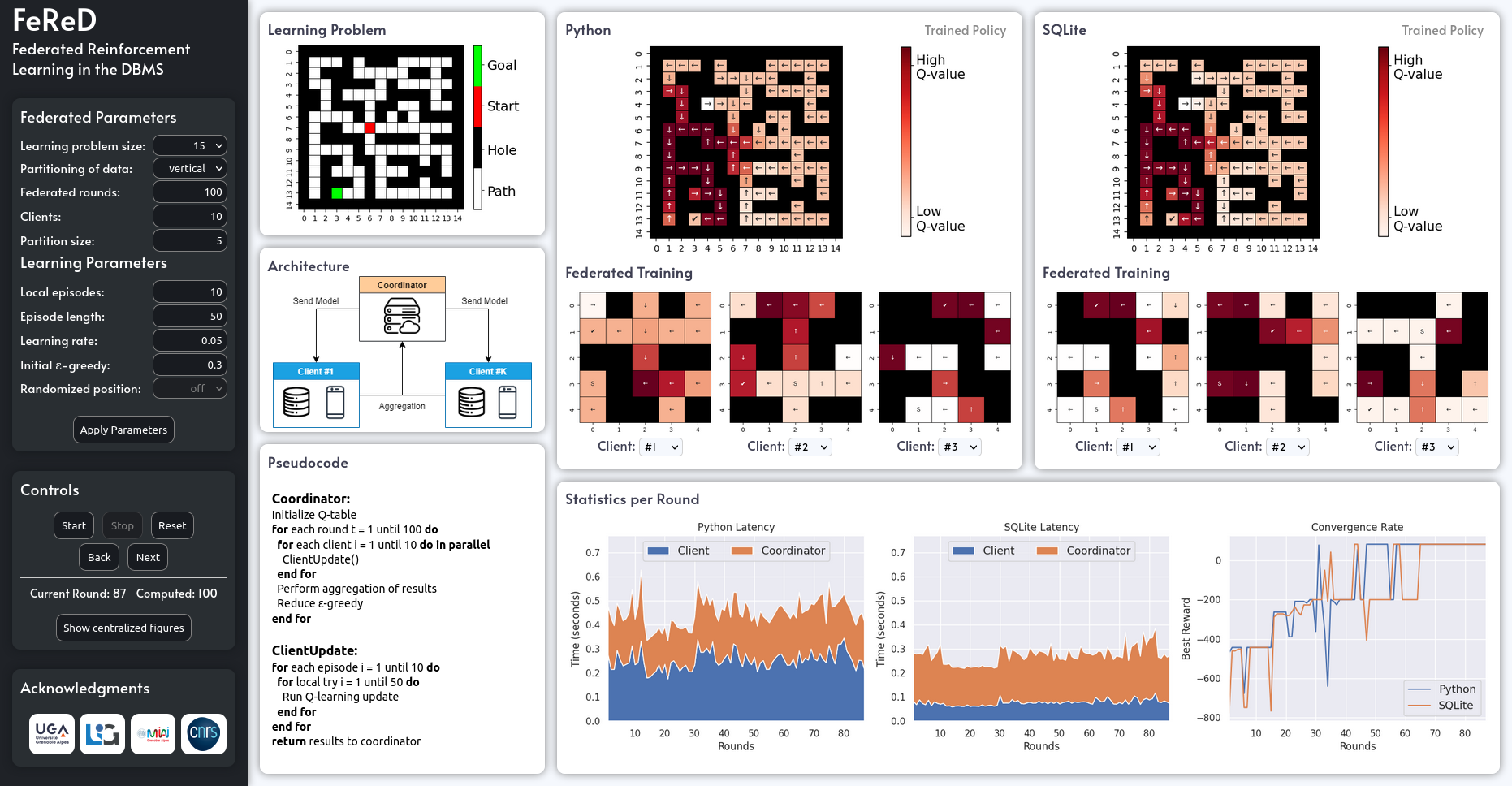
In more detail these are the options of each zone:
Interaction (Zone A)
- Federated Parameters. Such parameters include the number of clients to be included in the federated learning protocol and the type of data partitioning, which can be horizontal or vertical.
- Learning Paramaters. Such parameters will influence the difficulty of the learning problem, via the selected number of Qlearning episodes, their respective episode length, as well as the position of the starting point with respect to the goal.
- Controls. The data scientist applies the aforementioned selected parameters and can also choose to observe the results in a stepby-step manner.
Setting (Zone B)
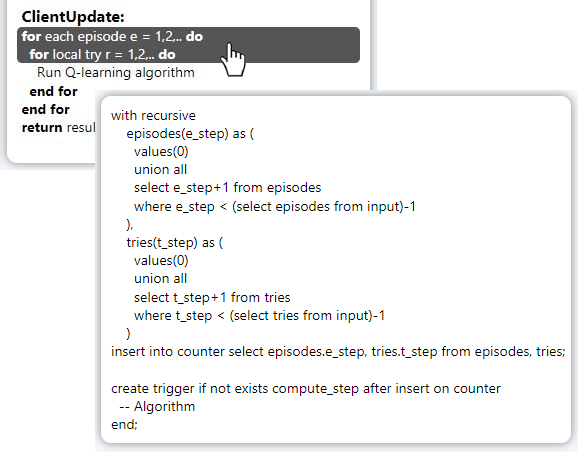
This zone depicts the selected setting as configured by the data scientist. We first see the learning problem (that is, the maze for which we compute an efficient Q-learning policy). As typical for a frozen lake problem, the goal, the holes, and the starting point are known in advance. In the end of Zone B there is a pseudocode. By selecting a line in the pseudocode, the data scientist activates a pop-up showing the corresponding code for the SQLite implementation.
Results (Zone C)
In this zone, FeReD compares Python vs SQLite implementations according to several performance measures. On top of Zone C, we show the global trained policy corresponding to the entire federated learning process in each implementation. The shade in each cell corresponds to their Q-value as learned by each implementation. The darker the shade, the higher the Q-value of the best action (shown by the arrow) of the cell.
Then, FeReD provides statistics per round. In the bottom-right of Zone C, FeReD displays the convergence rate of the two implementations. We notice that both implementations behave similarly in the attainable best cumulative rewards per round, and converge after the same number of federated rounds. FeReD also displays the time needed for the clients and the coordinator in the two implementations.
Demonstration Scenarios
The users play the role of a data scientist who seeks to gather information about the best configuration for a federated reinforcement learning protocol. The users will simulate entire workflows of FeReD, configuring the learning problem and observing the different performance measures contrasting the SQLite and Python implementations on the clients’ side. From a top view, FeReD allows users to achieve the following:
- Examine types of data partitioning. The first scenario highlights the differences between SQLite vs Python implementations in vertical vs horizontal data partitioning scenarios, each contrasting the learning performance and the time required for each client to perform local computations.
- Examine SQL expressiveness. The second scenario is focused on the comparison of the expressiveness and succinctness of the two equivalent implementations on the client side (local computations) in federated Q-learning.
Results
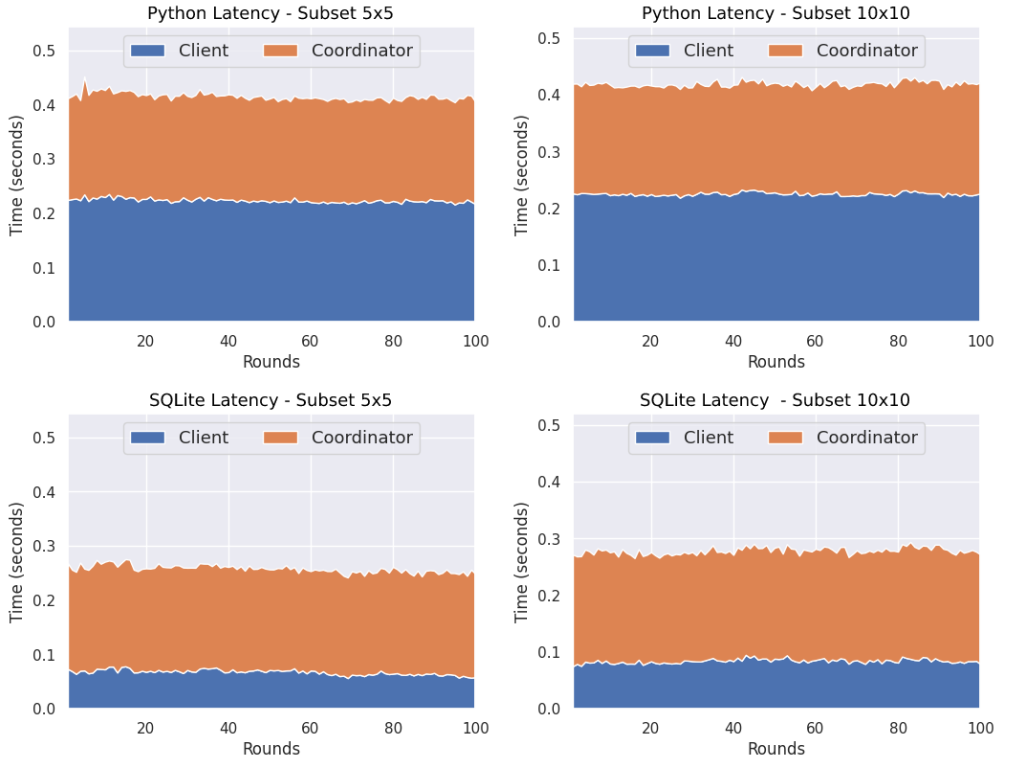
After carrying out some tests in both types of data partitioning, we found out the following. In a horizontal setting, SQLite seems to be behaving very similar to a Python implementation, but slower in the beggining. This also depends on the scale of the problem at hand.
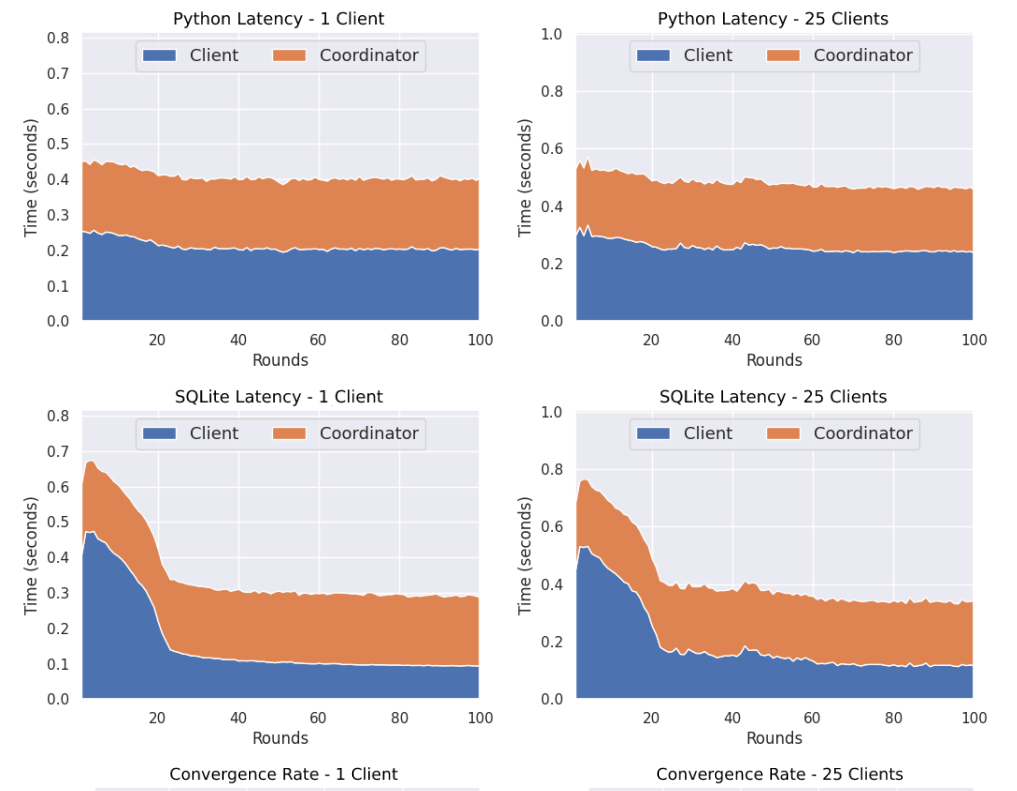
On the other hand in a vertical partitioning setting, SQLite proves to be a lot faster (usually more than 50%) from a pure Python implementation. Here the scale of the learning problem does not matter, as it is split across all of the participating learning devices.
Citation
If you are using this source code in your research please cite:
- Sotirios Tzamaras, Radu Ciucanu, Marta Soare, Sihem Amer-Yahia. FeReD: Federated Reinforcement Learning in the DBMS. Proceedings of the 31st ACM International Conference on Information and Knowledge Management (CIKM).
@inproceedings{TzamarasCSA22,
author = {Sotirios Tzamaras and Radu Ciucanu and Marta Soare and Sihem Amer{-}Yahia},
title = {FeReD: Federated Reinforcement Learning in the DBMS},
booktitle = {Proceedings of the 31st {ACM} International Conference on Information {\&} Knowledge Management, Atlanta, GA, USA, October 17-21, 2022},
publisher = {{ACM}},
year = {2022}
}